はじめに
R/OCRとは?
画像、PDFから表示されている文字をテキストデータに変換するサービスです。
- 書類をデジタル化、正規化することにより、文字列としての検索やコピー&ペーストが可能に!
- 業務効率化によりヒューマンエラーを低減!
- 高精度な「AI-OCR」により97〜98%の認識率を実現!
- ペーパレス化の促進!
- 専用サーバーで運用!機密データも安心!
まずはOCRを実行してみましょう
実行するだけなら簡単です!
-
ファイル登録からファイルをアップロードする
アップロード可能なファイルは GIF JPEG PNG PDF
1ファイルにつき、16Mバイトまで - ファイル一覧からアップロードしたファイルを表示する
-
アップロードしたファイルを確認してください!PDFの場合もし、PDFにテキストが埋め込まれている場合以下の内容で取り出すのが確実です。
-
PDFに埋め込まれたテキストを抽出するをクリックし有効にする
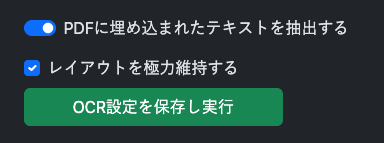
- OCR設定を保存し実行
-
右下 文字起こしテキストを保存 を押下

もしテキストが埋め込まれていない場合、その他画像ファイルと同様に以下からOCRを実行してください。画像ファイルの場合表示内容すべてをそのまま取得するのであれば1アクションです。-
右上 OCR設定を保存し実行予約 を押下
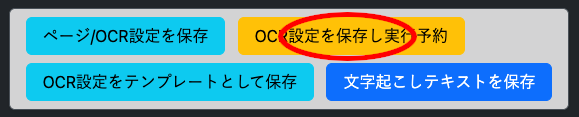
ファイルの内容によりますが少し時間がかかります。 -
PDFに埋め込まれたテキストを抽出するをクリックし有効にする
- 文字起こしテキストに抽出されたテキストが登録されています
作業の効率を上げましょう!
もし、同じ書式のファイルをアップロード、OCRを実行するのであればテンプレート機能が便利です。
- アップロードされているファイルを表示する (ファイル一覧から表示してください)
-
すでに、文字起こしテキストがうまくできているのであれば、その設定のままでOK
まだうまくできていないのであれば、OCR設定を確認し調整する。 -
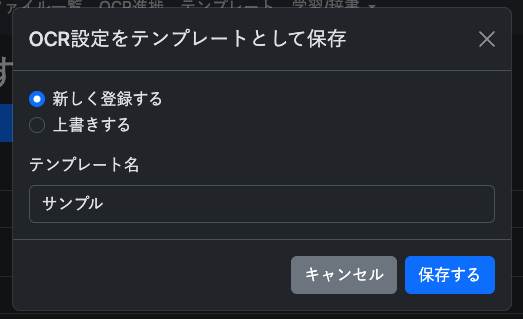
左下 OCR設定をテンプレートとして保存 を押下

-
新しく登録する / 上書きする を選択し、テンプレート名を入力、保存を押下してください。
-
作成したテンプレートは各アップロード済みファイルに対しても利用できます。
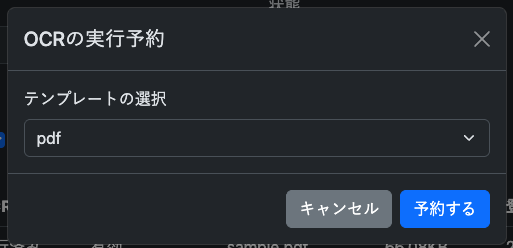
また、もしそのまま使えるテンプレートなのであれば、ファイル一覧の各ファイル、名称の左のチェックボックスを利用し、ページ下部、OCR実行予約 を押下

利用するテンプレートを選択の上、予約する を押下することでテンプレートを利用した一括予約が可能です。
OCRの精度を上げるには
学習辞書、読み取り方、読み取り動作ももちろん大事な内容ですが、一番効果が高いのはOCRを実行するファイルの状態です。
文字の大きさ、画像のノイズ、傾きなど、AIが読み取りやすい状態で実行することが望ましいとされています。
OCR設定に各フィルタをご用意しております。もしそれらを使うことにより制度が上がるのであれば是非ご利用の上OCRを実行してください。
文字のサイズが小さすぎる、もしくは大きすぎる場合など、ある程度の拡大は可能ではありますが、少なからず画像自体の劣化が発生するため、可能であれば文字サイズが大きいものをご用意の上ファイルを登録してください。
OCR設定 対象画像の設定についてはこちらも参照してください。
OCR設定 読み取り設定についてはこちらも参照してください。
特定の文字の誤認識を防ぐには
学習データモデルの作成で改善する可能性があります。
ものすごく強力な機能にはなりますが、学習させるデータ量や質、記載の仕方によって結果がかなり変わってきてしまうため簡単ではありません。
また、こう書けば必ずこうなる、というルールが存在するわけでもないため、ある程度試行錯誤し辞書を作っていく形となります。
学習データについてはこちらも参照してください。